自然语言处理中为了计算文档之间的相似度,往往需进行文档的量化表示,下面关于BOW(即Bag-Of-Words model)和VSM(Vector Space Model)的描述正确的是:
A BOW,即词袋模型。即为了计算文档之间的相似度,假设可以忽略文档内的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合。
B VSM,即向量空间模型。是一种表示文本文档的数学模型。将每个文档表示成同一向量空间的向量。
C 在VSM,即向量空间模型中,所有文档的向量维度的数目都相同。
D 其它选项都不对
(2)单选题为了在python程序中进行英文自然语言的处理,如词语切分(Tokenization)词干提取(Stemming)等工作,需要使用的导入模块语句通常为:
A import matplotlib.pyplot as plt
B import nltk
C import numpy as np
D from sklearn import svm, datasets
(3)单选题为了进行中文的分词或者词性标注等处理,可以使用的导入模块语句为:
A import matplotlib.pyplot as plt
B import numpy as np
C import jieba
D from sklearn import svm, datasets
(4)多选题对于文本“I like to eat apple”,则下列关于N-gram的描述正确的是
A 其Uni-gram为“I”,“like”, “to”,“eat”,“apple”
B 其Bi-gram为“I like”,“like to”, “to eat”,“eat apple”
C 其Tri-gram为“I like to”,“like to eat”, “to eat apple”
D 其它选项都不对
(5)单选题关于特征降维方法有线性判别分析(LDA)和主成分分析法(PCA),错误的是
A LDA和PCA的共同点是,都可以将原始的样本映射到维度更低的样本空间
B LDA是为了让映射后的样本有最好的分类性能。即LDA是一种有监督的降维方法
C PCA是为了让映射后的样本具有最大的发散性,即PCA是一种无监督的降维方法
D LDA和PCA都是有监督的降维方法
(6)单选题对于下面的一段python程序,计算的是向量之间的
import numpy as np
x=np.random.random(5)
y=np.random.random(5)
sim=np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y))
A 欧氏距离
B 余弦相似度
C 欧式相似度
D 马修相关系数
(7)单选题对于下面的一段python程序,sim中保存的是向量之间的:
import numpy as np
x=np.random.random(5)
y=np.random.random(5)
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
sim=1-pdist(X,'cosine')
A 欧氏距离
B 余弦相似度
C 余弦距离
D 马修相关系数
(8)单选题下面的一段python程序的目的是使用主成分分析法(principal component analysis) 对iris数据集进行特征降维,以便于数据的二维平面可视化。则其中空格处应该填充的数字为?
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.target
pca = PCA(n_components= )
reduced_X = pca.fit_transform(X)
A 1
B 2
C 3
D 4
(9)单选题下图是使用主成分分析法对iris数据集进行特征降维并进行二维平面可视化的结果。则为了绘图,需要使用的导入语句是下面哪一种?
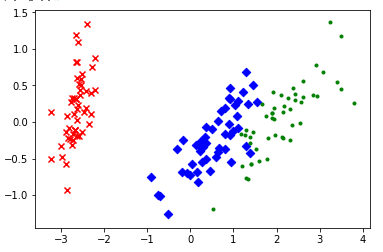
A import matplotlib.pyplot as plt
B from sklearn.decomposition import PCA
C from sklearn.lda import LDA
D import numpy as np
(10)单选题下面哪一条语句是用于导入nltk中的英文词性标注的模块?
A from nltk import word_tokenize
B from nltk.stem import PorterStemmer
C from nltk import pos_tag
D from nltk.corpus import treebank
获取标准答案请阅读全文
未经允许不得转载!第二讲 作业【含答案】 深度学习基础